


{kind=link}
Data Science seems to be unstoppable in the Pakistani market. In a 2016 interview, the Chief Technology Officer of Teradata viewed three Pakistani sectors as important adaptors of Data Science. These included the financial, telecommunication, and government sector.
Today, as we visit popular job portals in Pakistan such as Glassdoor and Linked In, and even the newest tech job portals such as Dicecamp jobs, we notice that the job updates keep on ballooning with every passing day as more and more companies call out for data scientist roles.
Data Science is a discipline of ‘advanced analytics’ and looks for ‘future trends’ using data on past events. In business, the data scientist teams work closely with historical data and use information of past events to support business decision making.
However, to lead a successful business decision, the business leaders’ understanding of the data science workflow is critical. Afterall a visionary leader can empower its data science team in the right way that leads to quality work, by the right people, using the right resources, and at the right time.
A 2022 survey by NewVantage Partners stresses on the need of such a visionary leader in the company’s leadership board. According to the survey, some 73.7pc of organizations now think that a Chief Data Analytics Officer- CDAO is critical to lead a data-driven initiative. The figure stood at 12.0pc in 2012 for the same organizations.
Contrary to this, when business leaders evade understanding the ‘Data Science workflow’, they fall deep into the data led troubles. These include; lack of employee confidence in data analytics, negative ROI (return on investment), or legal constraints from poor data governance.
The right perspective of Data Science in Business
Understanding the stages in the data science process helps leaders to recognize the right people, the right resources, and the right amount of time that’s required to accomplish a data science project.
Data Science Workflow
There are three stages of the data science workflow as shown in the infographic. Each stage requires a sub process that effectively caters the data at that stage.
- First stage is the data stage where the most relevant data is collected from company-owned databases, or from third party agencies such as marketing research bodies.
The company might be generating structured data, unstructured data or both. The technology requirements are different for structured and unstructured data. It’s critical for a business to decide which kind of data its systems generate. The business might also want to process both kinds of data and acquire solutions for both.
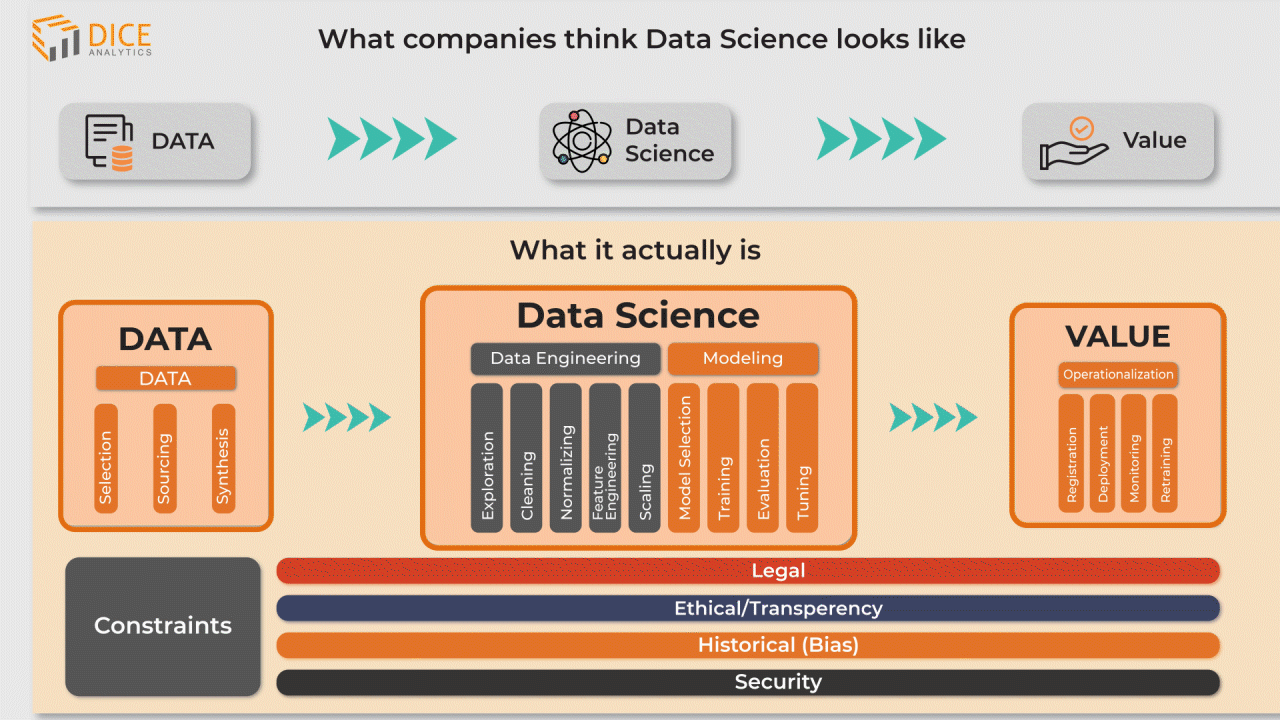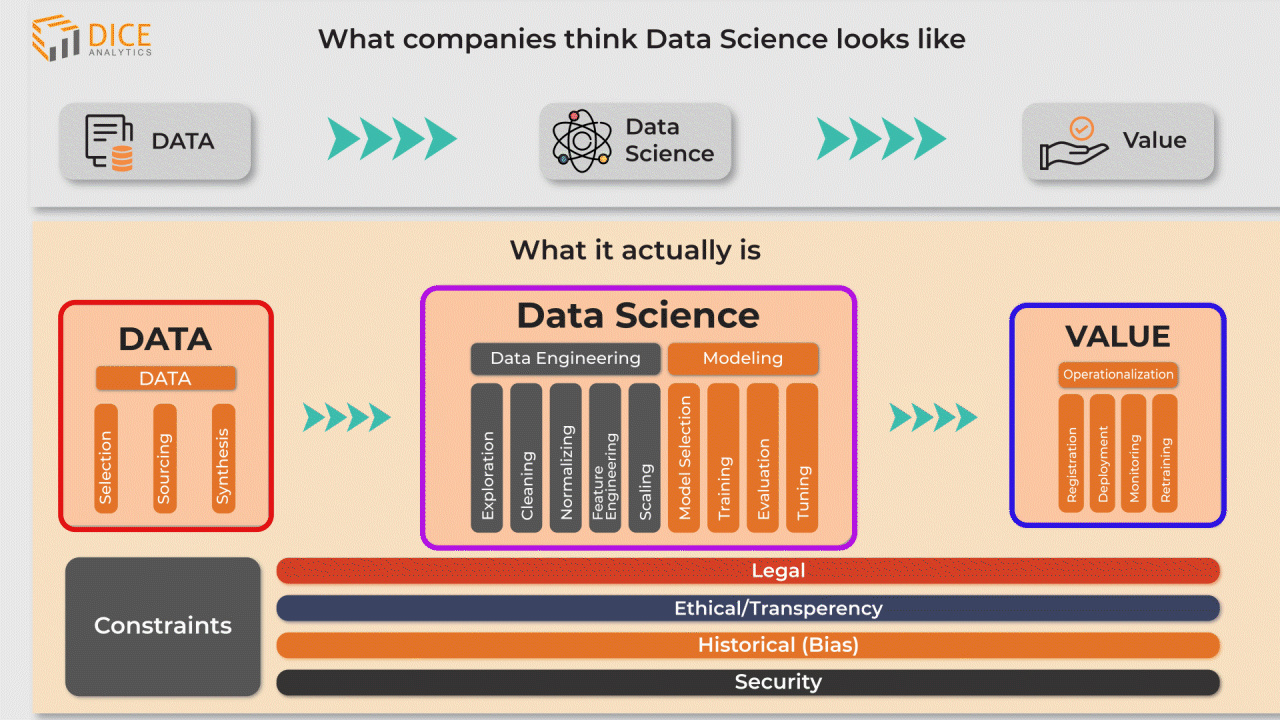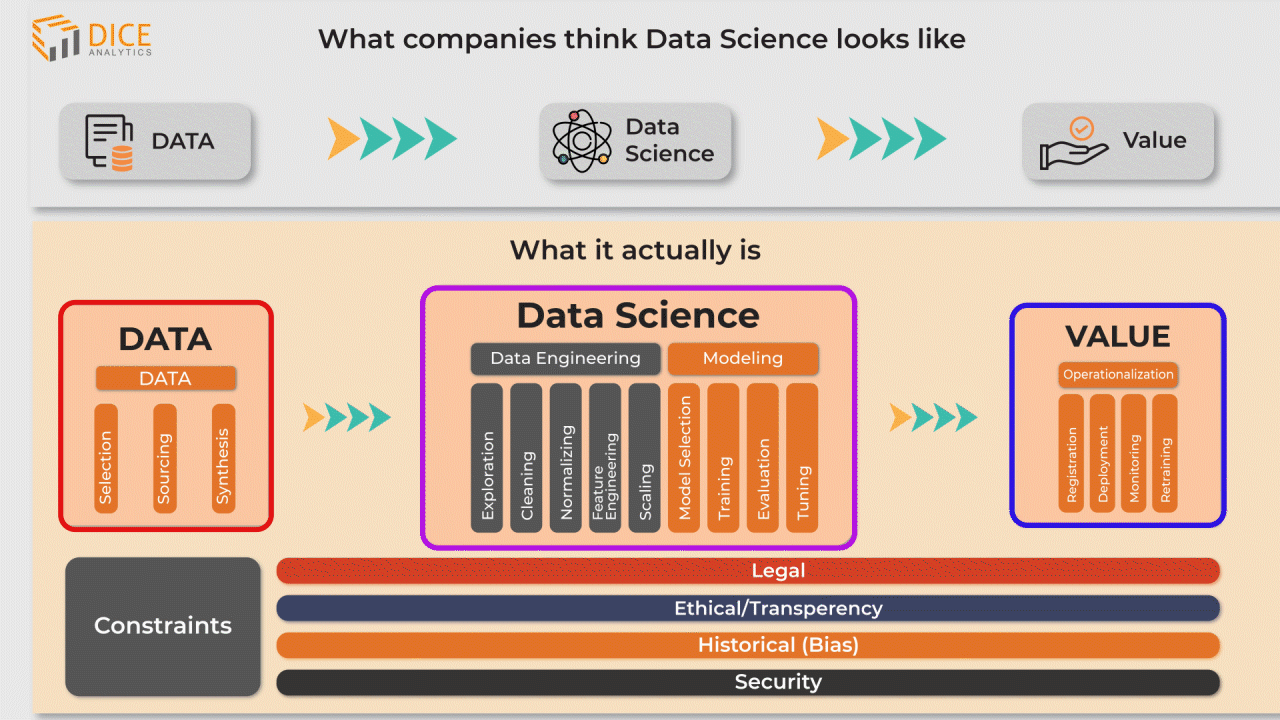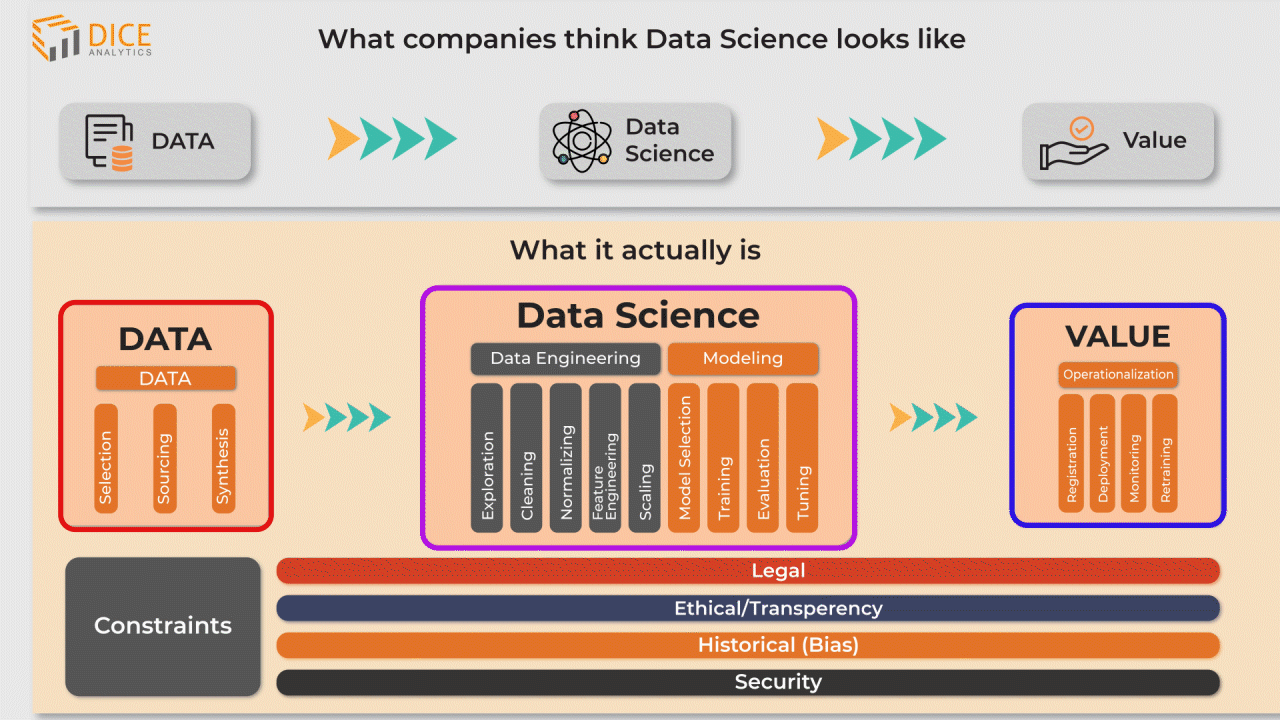
2. Now the data enters the data science stage. There are two main sub-stages here; these are the data engineering, and data modeling stages.
The raw data that arrived from the data stage is in unorganized form. It needs some engineering to arrange data contents into a structure that enables efficient storage, as well as optimized query processing.
For this purpose a data engineer examines and cleanses the data. Normalization techniques are applied to divide large sets of data into smaller sets; this removes redundancy, and maintains data integrity.
Once the data is structured it’s now used for feature engineering. It combines various data elements together to construct a feature. For example, information of ‘customer demographic’ and their ‘product purchase’ could be combined to form a feature that represents which customers prefer what kind of product.
Features are calculated from the historical data.
Note: The data engineering process could be automated to apply same transformations on new data that might be scheduled per day or is live data. However, sometimes it’s best to avoid a fixed engineering schema for all data. This ensures more flexibility by providing autonomy to model new data as per the engineer’s choice.
In the machine learning sub-stage, a machine learning model is designed as per the data and it uses the features as training data.
A machine learning model is a statistical formula that looks for the same features, in the new data, that it was used to train earlier.
It’s important to test and validate the model before deploying it to check if it’s actually extracting correct features and making the correct predictions. If the model has low accuracy, it gets further tuning.
3. In the value stage the machine learning model is ready to be taken into the operational environment of the organization. This means connecting your model (deployment) with data sources to automatically implement stage 1 and stage 2 of the data science process as new data comes in. This new data is used as training data that retrains the model.
Data Constraints
Data constraints are the legal concerns on Data that limit data scientists to use data in a certain way. Not fulfilling the legal data constraints leads an organization towards reputational damage and legal liabilities.
Legal constraints on data entails:
Ethical/Transparency: The business needs to convey to its stakeholders as to how the machine learning model reached a certain decision.
Algorithmic Fairness: The business needs to make sure if its algorithms are making fair decisions for all customer groups? Are some customer groups being discriminated against?
Data Privacy: The business needs to make sure that customer data privacy is maintained under the legal privacy agreements (such as GDPR in Europe and CPRA in the US).
Data Security: The business needs to make sure if the data science workflow is secure from hackers and security breaches?
Acquire the right Data Science skills
A short training course on data science can enable an organization to effectively plan and manage data science workflow. Dice Analytics offers a two month long training course that’s effectively customized to meet the needs of its audience.
Visit our platform today and consult for hands-on training on our landmark course of Data Science and Machine Learning.
About Dice Analytics
Dice Analytics is Pakistan’s top analytics training brand and largest AI service provider. We are the fastest growing business based in Pakistan.
Dice analytics has empowered the BI ecosystem of Pakistan in its five year journey delivering 150+ public and 20+ corporate trainings.
Our notable customers include: Pakistan Air Force, NCOC, STC, Huawei, Jazz, Zong, Nayatel, Askari Bank, IEEE, and Bata.
Visit our website for more information.